在转录组数据分析中,研究者通常会在差异表达分析前先过滤掉低表达基因。这个看似简单的预处理步骤,实际上对后续统计分析的准确性和可靠性有着很重要影响。为什么不保留所有基因进行分析呢?
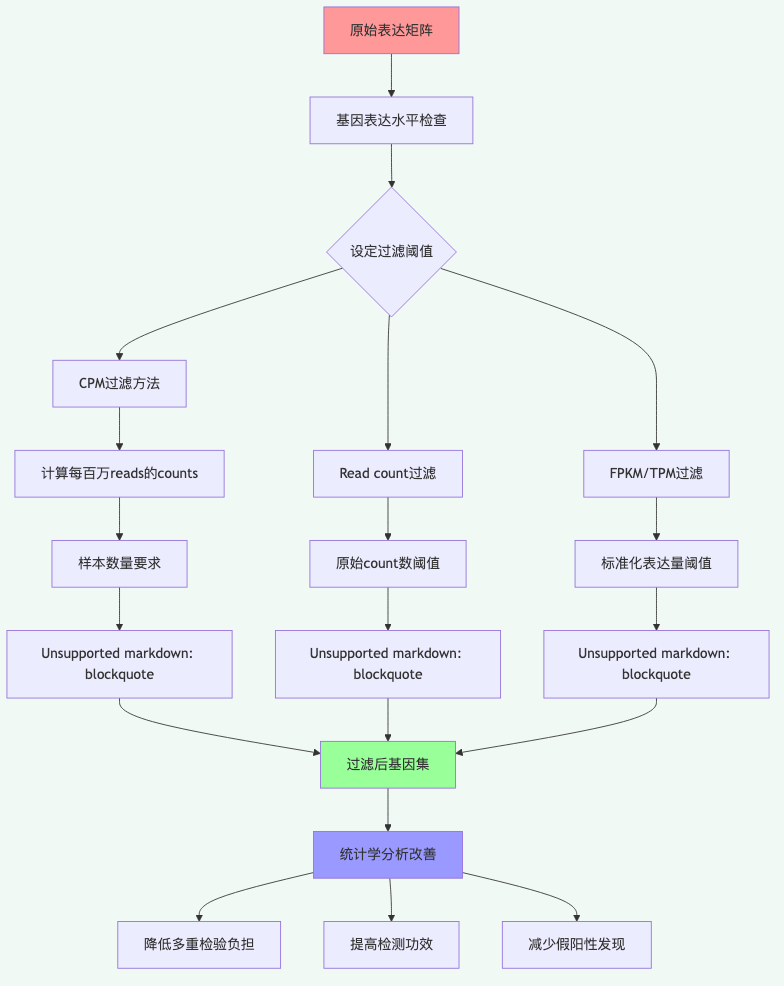
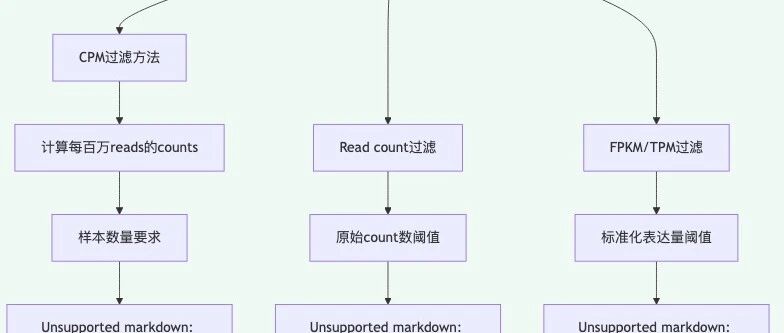
图 1 低表达基因过滤的标准工作流程:多种过滤方法可供选择,最终改善统计学分析。
基因表达数据中存在大量表达水平极低或在多数样本中不表达的基因。这些基因的读数往往接近测序本底噪音,其表达变化更多反映的是技术变异而非真实的生物学差异。如果直接纳入统计分析,不仅会引入噪音,还会显著增加多重检验的负担。
过滤低表达基因的核心目的是提高下游分析的统计功效。常用的过滤标准包括CPM(每百万reads的count数)、原始read count,或标准化后的FPKM/TPM值。最常见的做法是要求基因在至少3个样本中的CPM值大于1,这个阈值对应大约10-15个原始reads。
表达分布特征分析
转录组数据中基因表达呈现典型的长尾分布,大部分基因表达水平较低,只有少数基因高表达。这种分布模式在所有物种中都相当保守。
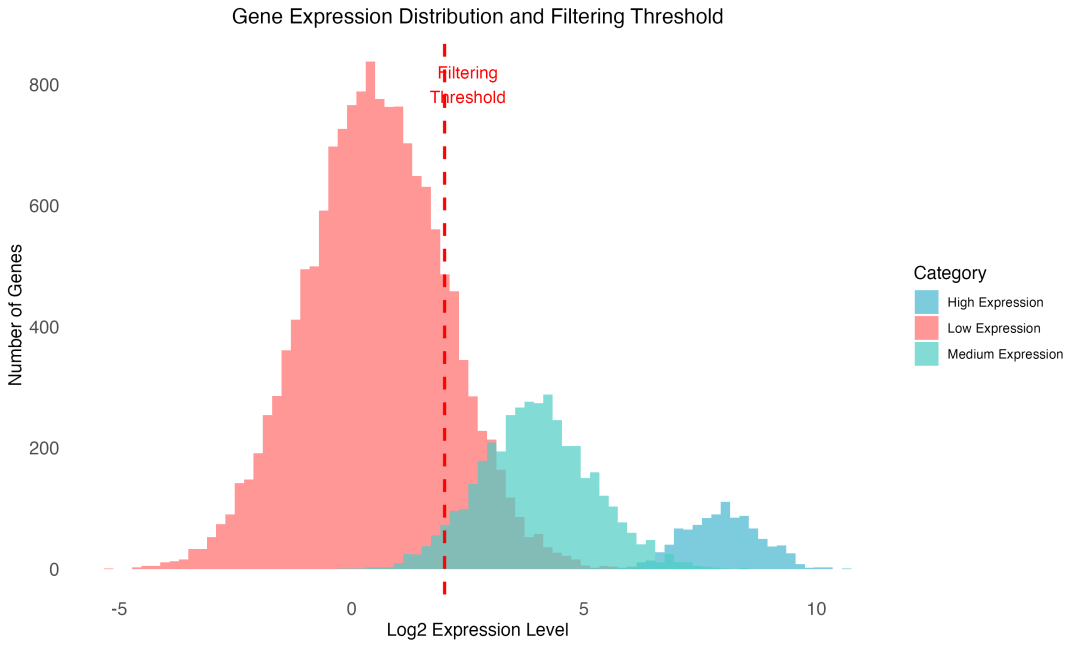
图 2 基因表达水平分布:红色虚线标示常用的过滤阈值位置。
从图中可以看出,低表达基因占据了基因总数的绝大部分。这些基因的表达信号往往被测序噪音淹没,其观察到的"表达变化"很可能是随机波动的结果。过滤这些基因不仅不会丢失有意义的生物学信息,反而能让我们更专注于真正有表达活性的基因。
更重要的是,低表达基因在统计检验中表现出不同的方差-均值关系。它们的方差往往相对较大且不稳定,这违背了许多差异表达分析方法的统计假设,可能导致错误的统计推断。
多重检验负担的缓解
过滤低表达基因最直接的好处是显著减少多重检验的负担。在基因组范围的差异表达分析中,我们可能同时检验数万个基因,每增加一个检验都会使多重检验校正更加严格。
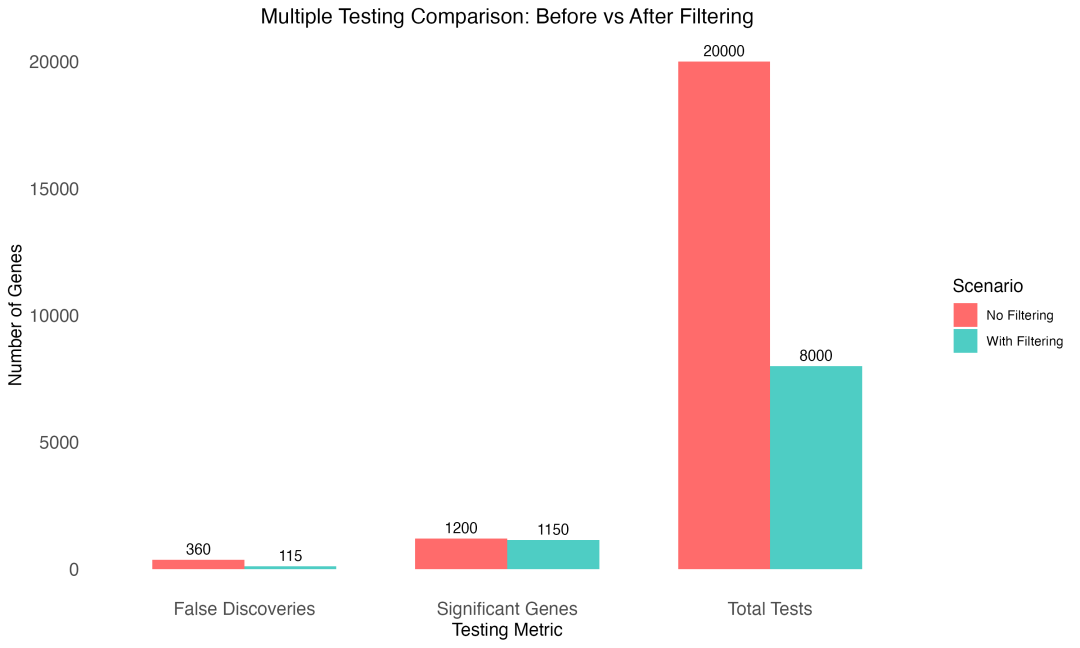
图 3 过滤前后的多重检验比较:过滤显著减少了假阳性发现数量。
从实际效果看,过滤掉约60%的低表达基因后,虽然检测到的显著差异基因总数略有下降,但假阳性发现率大幅降低。这意味着剩余的显著基因具有更高的可信度,研究结论更加可靠。
此外,减少检验数量还能提高统计功效,使我们更容易检测到真正的差异表达基因。这是一个典型的"少即是多"的例子——通过去除噪音,我们获得了更清晰的信号。
总结一下
过滤低表达基因是转录组分析中的重要质控步骤,它通过去除噪音基因、减少多重检验负担和提高统计功效,显著改善了差异表达分析的准确性。这个看似简单的预处理步骤,体现了生物信息学中"预防胜于治疗"的重要原则。

以上就是今天的内容,希望对你有帮助!欢迎点赞、在看、关注、转发。