最近看了一个系统设计的why design系列,就想着生信分析也出一期《为什么这么设计》,因为我发现很多同学只知道一个生信分析术语,但是并不知道背后的原理、本质等,就打算码一个 why design 系列。
今天讲的是 为什么需要做GO/KEGG富集分析?
得到差异表达基因列表后,面对成百上千个基因名称,研究者往往感到困惑:这些基因到底在告诉我们什么生物学故事?GO/KEGG富集分析就是破解这个谜题的关键工具。
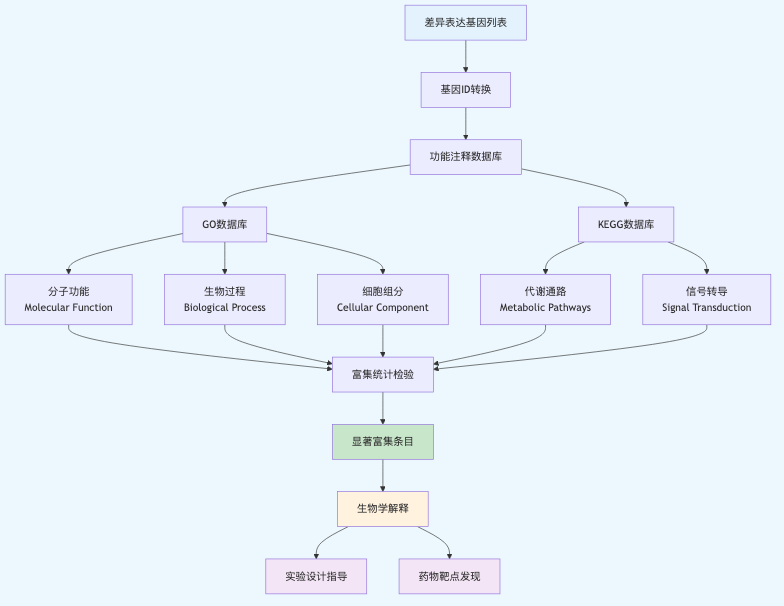
图 1 GO/KEGG富集分析的完整流程:从基因列表到生物学洞察的转化过程。
从基因列表到生物学意义
单纯的差异基因列表只能告诉我们"哪些基因发生了变化",却无法回答"为什么会发生这些变化"以及"这些变化意味着什么"。GO(Gene Ontology)和KEGG(Kyoto Encyclopedia of Genes and Genomes)数据库为我们提供了系统化的功能注释框架。
GO数据库将基因功能分为三大类:分子功能(做什么)、生物过程(参与什么)、细胞组分(在哪里)。KEGG则专注于代谢通路和信号转导网络,描述基因间的相互作用关系。
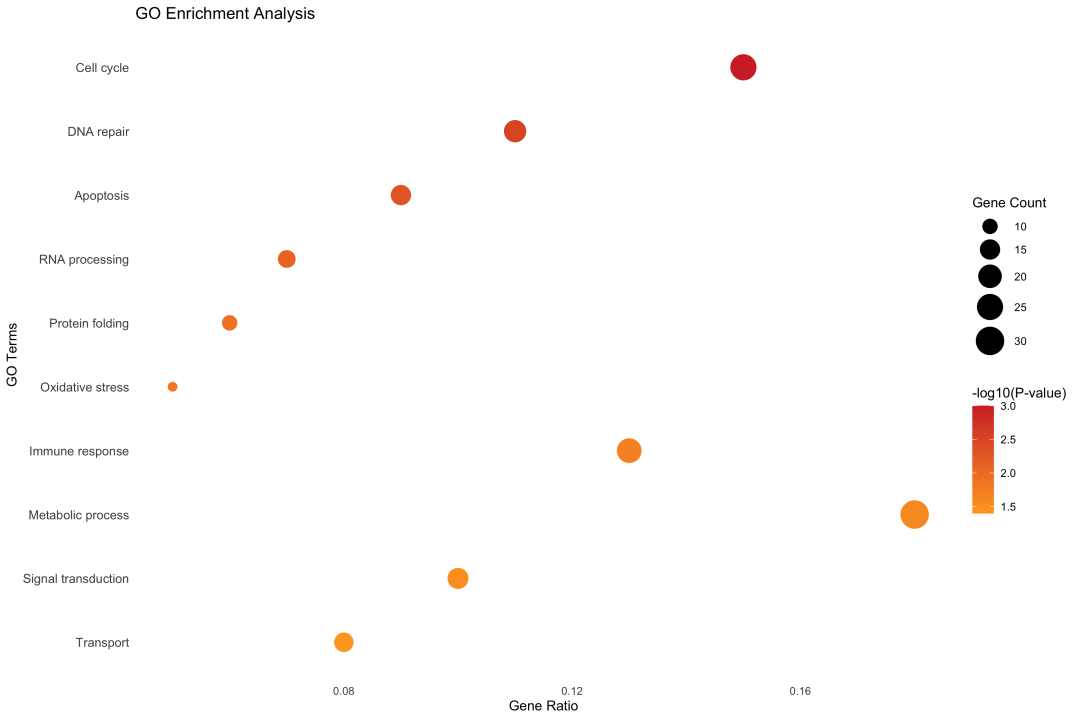
图 2 GO富集分析结果示例:气泡大小表示基因数量,颜色深浅代表显著性水平。
统计学原理与假设检验
富集分析的核心是 超几何检验 ,用于判断差异基因在特定功能类别中的富集程度是否超出随机期望。
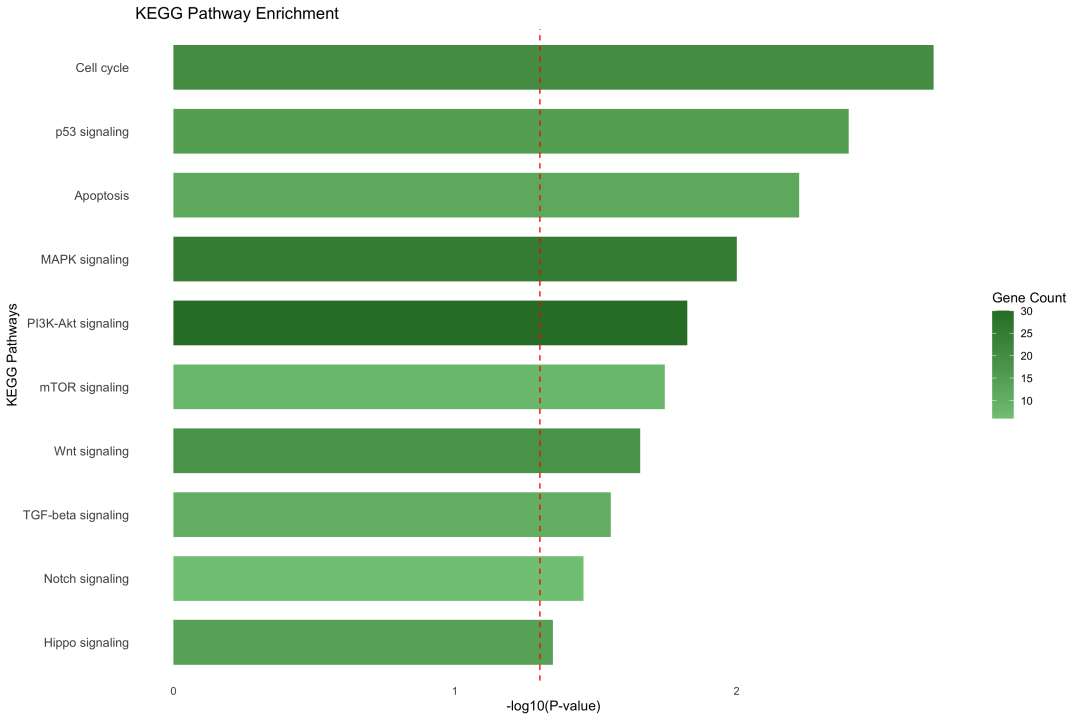
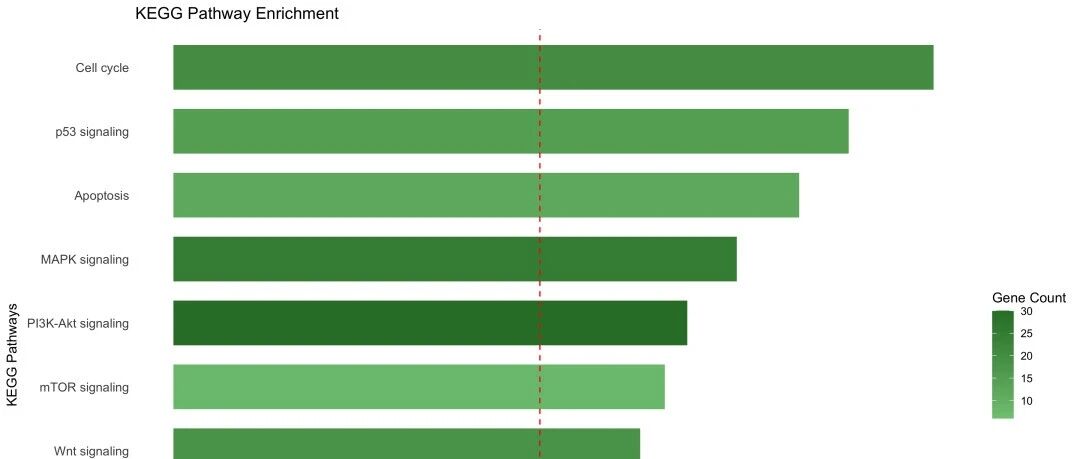
图 3 KEGG通路富集结果:红色虚线表示显著性阈值(P < 0.05)。
假设我们有20,000个背景基因,其中200个属于某个GO条目,我们的500个差异基因中有30个属于该条目。超几何检验计算的是:在随机抽取500个基因的情况下,获得30个或更多该条目基因的概率。
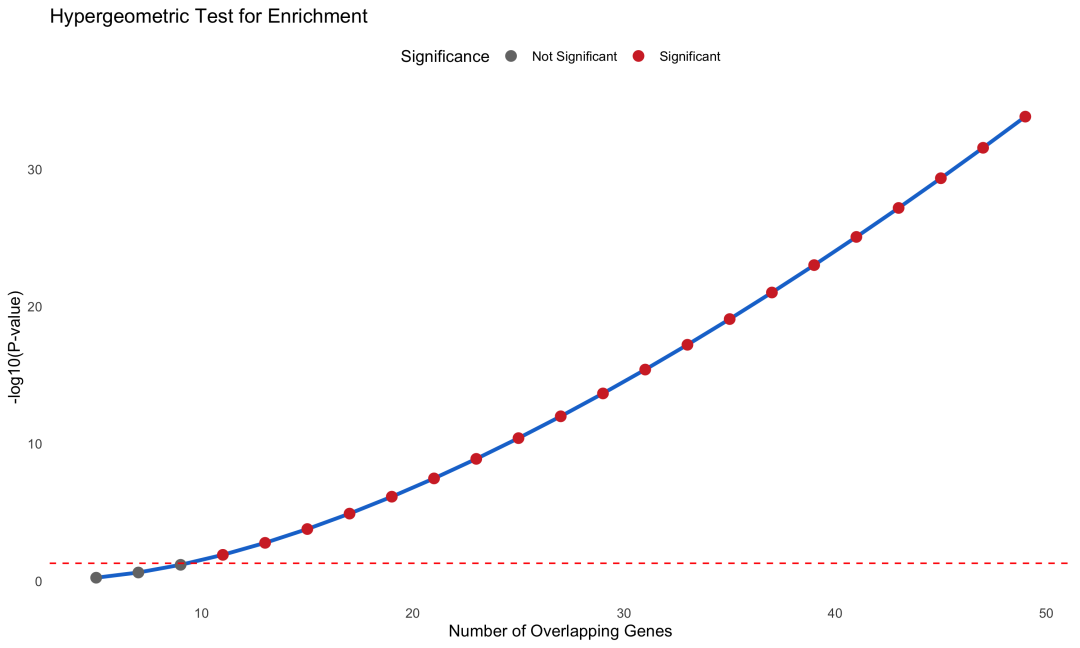
图 4 超几何检验的统计原理:重叠基因数与显著性的关系。
多重检验校正的必要性
当同时检验数千个GO条目或KEGG通路时,会面临 多重比较问题 。即使每个检验的假阳性率为5%,检验1000个条目就可能产生50个假阳性结果。
常用的校正方法包括:
-
Bonferroni校正 :保守但严格控制整体假阳性率 -
FDR(False Discovery Rate) :在发现能力和假阳性控制间取得平衡 -
q值 :FDR的改进版本,更适合大规模基因组学数据
生物学解释的桥梁
富集分析的真正价值在于搭建了基因表达变化与生物学现象之间的桥梁:
-
机制洞察 :揭示疾病发生的分子机制 -
药物靶点 :识别潜在的治疗干预点 -
实验设计 :为后续验证实验提供方向 -
通路串联 :理解多个生物过程间的关联
写在最后
GO/KEGG富集分析将分散的基因信息整合为有序的生物学知识,是从数据到发现的重要一步。在后基因组时代,掌握这种"翻译"能力,才能真正让海量的组学数据为生物医学研究服务。
以上就是今天的内容,希望对你有帮助!欢迎点赞、在看、关注、转发。