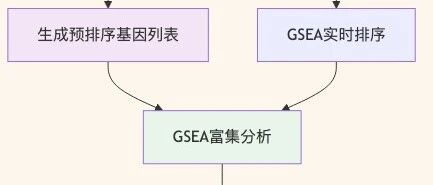
在基因富集分析中,GSEA(Gene Set Enrichment Analysis)提供了两种主要的分析模式:使用预排序基因列表(preranked)和实时排序分析。为什么越来越多的研究者倾向于使用预排序列表进行GSEA分析?
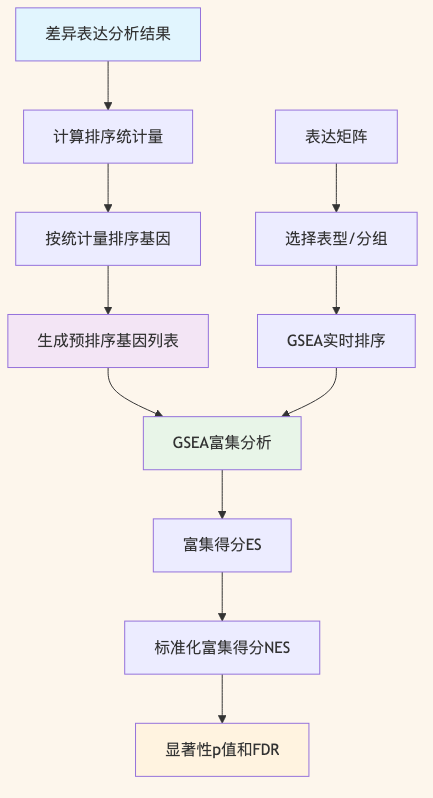
图 1 GSEA分析流程对比:预排序模式(左侧)vs 实时排序模式(右侧)的核心步骤差异。
传统的GSEA分析需要提供完整的表达矩阵和表型信息,软件会在分析过程中实时计算基因的排序统计量。而预排序模式则要求用户预先计算好基因的排序指标(如log2FC、t统计量等),并按此指标对所有基因进行排序,形成一个有序的基因列表。
计算效率的显著提升
预排序列表的最大优势在于计算效率。当使用传统模式时,GSEA需要重复计算基因间的相关性和排序统计量,特别是在大型数据集中,这个过程可能耗时数小时。而预排序模式跳过了这些重复计算,直接基于用户提供的排序结果进行富集分析,将分析时间缩短至分钟级别。
此外,预排序模式对内存的要求也更低。传统模式需要将整个表达矩阵载入内存并进行矩阵运算,而预排序模式只需要处理一维的基因列表,大大降低了内存占用。
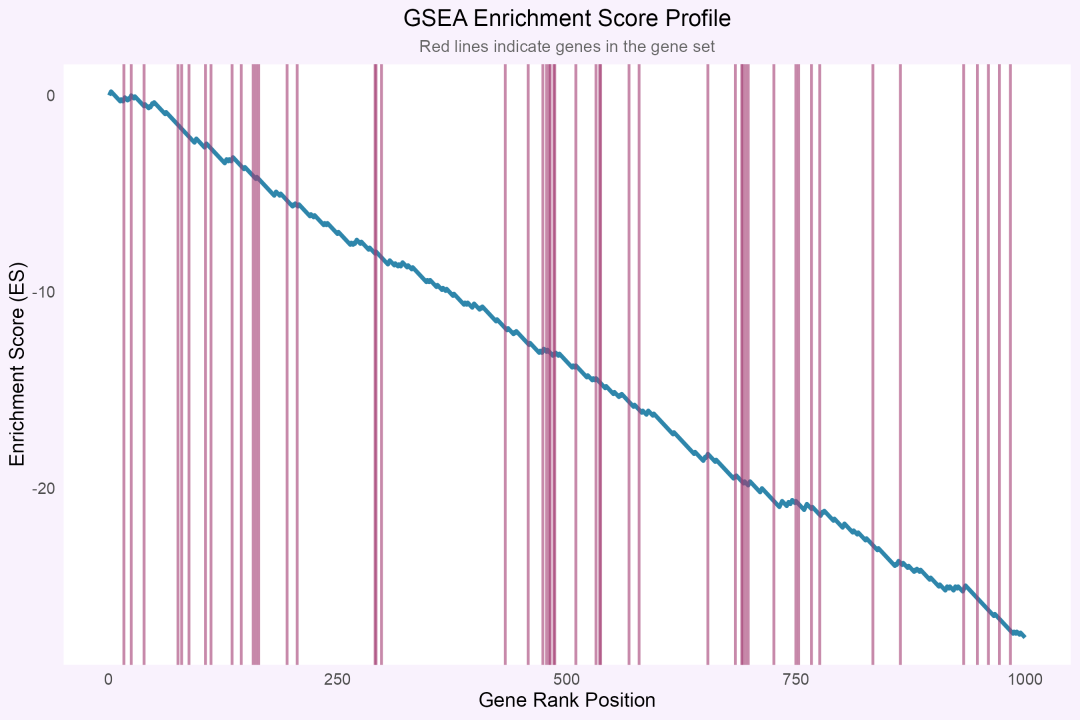
图 2 GSEA富集得分曲线示例:红色竖线标记基因集中的基因位置,蓝色曲线展示累积富集得分变化。
结果的可重现性保证
使用预排序列表还能显著提高分析结果的可重现性。在传统模式下,由于随机种子、计算精度等因素的影响,同样的数据可能产生略有差异的排序结果。而预排序模式中,排序步骤与富集分析步骤完全分离,只要使用相同的预排序列表,就能保证完全一致的分析结果。
这种可重现性对于科研发表和结果验证至关重要。研究者可以将预排序列表作为补充材料提供,其他人可以完全重现相同的富集分析结果。
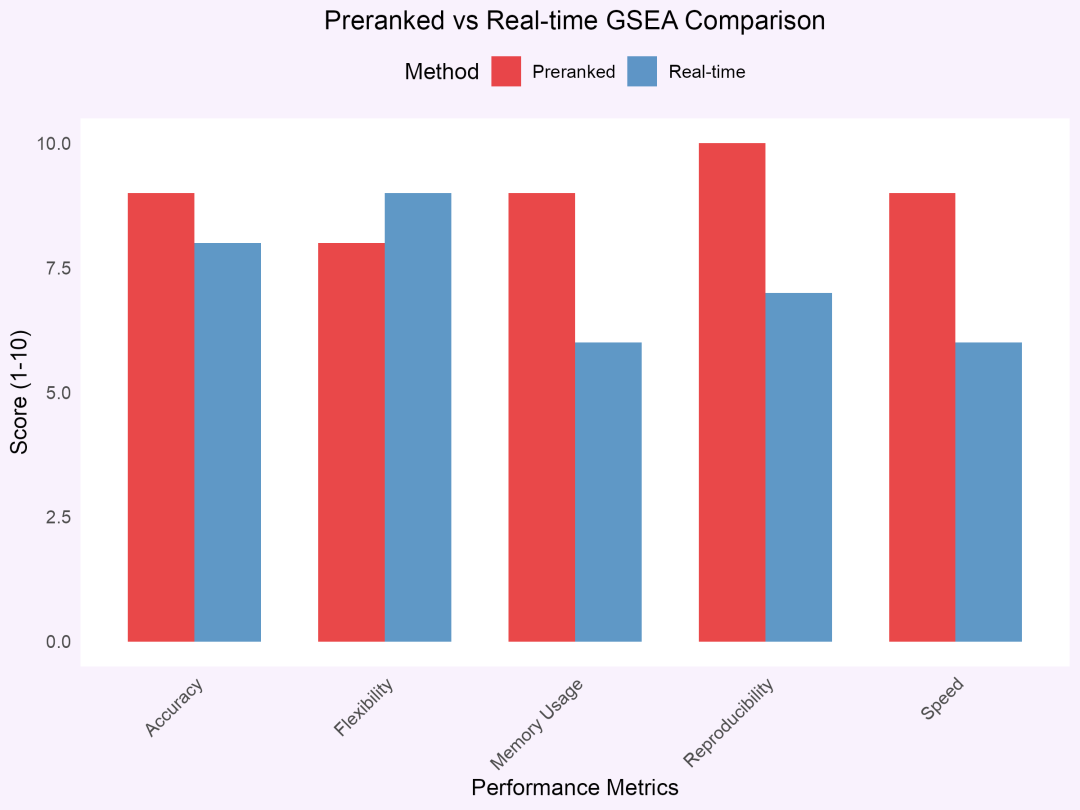
图 3 预排序与实时排序GSEA方法在多个性能指标上的对比评估。
灵活性与兼容性优势
预排序模式还提供了更高的分析灵活性。研究者可以根据具体的研究问题选择最合适的排序指标,比如在差异表达分析中可以使用log2FC、t统计量、或者综合考虑效应大小和显著性的复合指标。这种灵活性在传统模式中往往受到软件内置算法的限制。
同时,预排序列表具有良好的兼容性,可以在不同的GSEA软件工具间无缝切换使用,为方法比较和结果验证提供了便利。
总jie
预排序列表在GSEA分析中的广泛应用,本质上体现了生信分析中"分而治之"的设计思想。通过将复杂的分析流程分解为独立的模块,既提高了计算效率,又增强了结果的可重现性和分析的灵活性。对于大多数转录组富集分析场景,预排序模式已成为首选策略。
以上就是今天的内容,希望对你有帮助!欢迎点赞、在看、关注、转发。